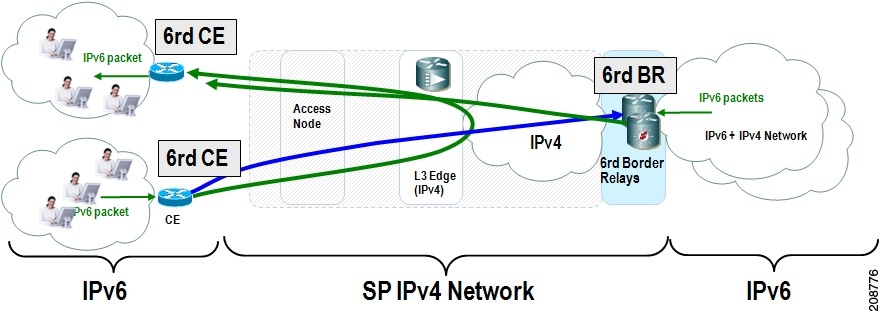
BGP Overview
BGP is an external gateway protocol, meant to be used between different networks. It is the protocol used between Internet service providers (ISPs) and also can be used between an Enterprise and an ISP. BGP was built for reliability, scalability, and control, not speed. Because of this, it behaves differently from the protocols covered so far in this book:- BGP stands for Border Gateway Protocol. Routers running BGP are termed BGP speakers.
- BGP uses the concept of autonomous systems (AS). An autonomous system is a group of networks under a common administration. The Internet Assigned Numbers Authority (IANA) assigns AS numbers: 1 to 64511 are public AS numbers and 64512 to 65535 are private AS numbers.
- Autonomous systems run Interior Gateway Protocols (IGP) within the system. They run an Exterior Gateway Protocol (EGP) between them. BGP version 4 is the only EGP currently in use.
- Routing between autonomous systems is called interdomain routing.
- The administrative distance for EBGP routes is 20. The administrative distance for IBGP routes is 200.
- BGP neighbors are called peers and must be statically configured.
- BGP uses TCP port 179. BGP peers exchange incremental, triggered route updates and periodic keepalives.
- Routers can run only one instance of BGP at a time.
- BGP is a path-vector protocol. Its route to a network consists of a list of autonomous systems on the path to that network.
- BGP's loop prevention mechanism is an autonomous system number. When an update about a network leaves an autonomous system, that autonomous system's number is prepended to the list of autonomous systems that have handled that update. When an autonomous system receives an update, it examines the autonomous system list. If it finds its own autonomous system number in that list, the update is discarded.
Use BGP when the AS is multihomed, when route path manipulation is needed, or when the AS is a transit AS. (Traffic flows through it to another AS, such as with an ISP.)
Do not use BGP in a single-homed AS, with a router that does not have sufficient resources to handle it, or with a staff that does not have a good understanding of BGP path selection and manipulation.
BGP Databases
BGP uses three databases. The first two listed are BGP-specific; the third is shared by all routing processes on the router:- Neighbor database: A list of all configured BGP neighbors. To view it, use the show ip bgp summary command.
- BGP database, or RIB (Routing Information Base): A list of networks known by BGP, along with their paths and attributes. To view it, use the show ip bgp command.
- Routing table: A list of the paths to each network used by the router, and the next hop for each network. To view it, use the show ip route command.
BGP Message Types
BGP has four types of messages:- Open: After a neighbor is configured, BGP sends an open message to try to establish peering with that neighbor. Includes information such as autonomous system number, router ID, and hold time.
- Update: Message used to transfer routing information between peers. Includes new routes, withdrawn routes, and path attributes.
- Keepalive: BGP peers exchange keepalive messages every 60 seconds by default. These keep the peering session active.
- Notification: When a problem occurs that causes a router to end the BGP peering session, a notification message is sent to the BGP neighbor and the connection is closed.
Internal and External BGP
Internal BGP (IBGP) is a BGP peering relationship between routers in the same autonomous system. External BGP (EBGP) is a BGP peering relationship between routers in different autonomous systems. BGP treats updates from internal peers differently than updates from external peers.Before any BGP speaker can peer with a neighbor router, that neighbor must be statically defined. A TCP session must be established, so the IP address used to peer with must be reachable.
In Figure 6-2, Routers A and B are EBGP peers. Routers B, C, and D are IBGP peers.
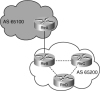
BGP Next-Hop Selection
The next hop for a route received from an EBGP neighbor is the IP address of the neighbor that sent the update.When a BGP router receives an update from an EBGP neighbor, it must pass that update to its IBGP neighbors without changing the next-hop attribute. The next-hop IP address is the IP address of an edge router belonging to the next-hop autonomous system. Therefore, IBGP routers must have a route to the network connecting their autonomous system to that edge router. For example, in Figure 6-3, RtrA sends an update to RtrB, listing a next hop of 10.2.2.1, its serial interface. When RtrB forwards that update to RtrC, the next-hop IP address will still be 10.2.2.1. RtrC needs to have a route to the 10.2.2.0 network to have a valid next hop.
To change this behavior, use the neighbor [ip address] next-hop-self command in BGP configuration mode. In Figure 6-3, this configuration goes on RtrB. After you give this command, RtrB advertises its IP address to RtrC as the next hop for networks from AS 65100, rather than the address of RtrA. Thus, RtrC does not have to know about the external network between RtrA and RtrB (network 10.2.2.0).
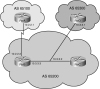
BGP Next Hop on a Multiaccess Network
On a multiaccess network, BGP can adjust the next-hop attribute to avoid an extra hop. In Figure 6-3, RtrC and RtrD are EBGP peers, and RtrC is an IBGP peer with RtrB. When C sends an update to D about network 10.2.2.0, it normally gives its interface IP address as the next hop for D to use. But because B, C, and D are all on the same multiaccess network, it is inefficient for D to send traffic to C, and C to then send it on to B. This process unnecessarily adds an extra hop to the path. So, by default, RtrC advertises a next hop of 10.3.3.3 (RtrB's interface) for the 10.2.2.0 network. This behavior can also be adjusted with the neighbor [ip address] next-hop-self command.BGP Synchronization Rule
The BGP synchronization rule requires that when a BGP router receives information about a network from an IBGP neighbor, it does not use that information until a matching route is learned via an IGP or static route. It also does not advertise that route to an EBGP neighbor unless a matching route is in the routing table. In Figure 6-3, if RtrB advertises a route to RtrC, then RtrC does not submit it to the routing table or advertise it to RtrD unless it also learns the route from some other IGP source.Recent IOS versions have synchronization disabled by default. It is usually safe to turn off synchronization when all routers in the autonomous system run BGP. To turn it off in earlier IOS versions, use the command no synchronization under BGP router configuration mode.
Configuring BGP
Before beginning to configure BGP, gather the network requirements you need, which should include the following:- Whether you need to run IBGP for internal connectivity
- External connectivity to the ISP
- Configuration parameters such as neighbor IP addresses and their AS number, and which networks you will advertise via BGP
Table 6-1. Basic BGP Configuration Commands
|
Command |
Description |
|
router bgp
AS-number
|
Starts the BGP routing process on the router. |
|
neighbor
ip-address
remote-as
AS-number
|
Sets up peering between BGP routers. IP address must match the source of routing updates. |
|
neighbor peer
-
group-name
peer-group
|
Creates a peer group to which you can then assign neighbors. |
|
neighbor
ip-address
peer-group
peer-group-name
|
Assigns a neighbor to a peer group. |
|
neighbor
ip-address
next-hop-self
|
Configures a router to advertise its connected interface as the next hop for all routes to this neighbor. |
|
neighbor
ip-address
update-source
interface-type number
|
Configures a router to use the IP address of a specific interface as the source for its advertisements to this neighbor. |
|
no synchronization
|
Turns off BGP synchronization. |
|
network
prefix
[
mask
subnet-mask
]
|
Initiates the advertisement of a network in BGP. |
BGP Network Command
In most IGPs, the network command starts the routing process on an interface. In BGP, the command tells the router to originate an advertisement for that network. The network does not have to be connected to the router; it just has to be in the routing table. In theory, it can even be a network in a different autonomous system (not usually recommended).When advertising a network, BGP assumes you are using the default classful subnet mask. If you want to advertise a subnet, you must use the optional keyword mask and specify the subnet mask to use. Note that this is a subnet mask, not the inverse mask used by OSPF and EIGRP network statements. The routing table must contain an exact match (prefix and subnet mask) to the network listed in the network statement before BGP advertises the route.
BGP Peering
BGP assumes that external neighbors are directly connected and that they are peering with the IP address of the directly connected interface of their neighbor. If not, you must tell BGP to look more than one hop away for its neighbor, with the neighbor ip-address ebgp-multihop number-of-hops command. You might use this command if you are peering with loopback interface IP addresses, for instance. BGP assumes that internal neighbors might not be directly connected, so this command is not needed with IBGP. If you do peer with loopback IP addresses, you must change the source of the BGP packets to match the loopback address with the neighbor ip-address update-source interface command.To take down the peering session with a neighbor but keep the neighbor configuration, use the neighbor ip-address shutdown command.
BGP Peering States
The command show ip bgp neighbors shows a list of peers and the status of their peering session. This status can include the following states:- Idle: No peering; router is looking for neighbor. Idle (admin) means that the neighbor relationship has been administratively shut down.
- Connect: TCP handshake completed.
- OpenSent, or Active: An open message was sent to try to establish the peering.
- OpenConfirm: Router has received a reply to the open message.
- Established: Routers have a BGP peering session. This is the desired state.
BGP Path Selection
IGPs, such as EIGRP or OSPF, choose routes based on lowest metric. They attempt to find the shortest, fastest way to get traffic to its destination. BGP, however, has a different way of route selection. It assigns various attributes to each path; these attributes can be administratively manipulated to control the path that is selected. It then examines the value of these attributes in an ordered fashion until it can narrow all the possible routes down to one path.BGP Attributes
BGP chooses a route to a network based on the attributes of its path. Four categories of attributes exist as follows:- Well-known mandatory: Must be recognized by all BGP routers, present in all BGP updates, and passed on to other BGP routers. For example, AS path, origin, and next hop.
- Well-known discretionary: Must be recognized by all BGP routers and passed on to other BGP routers but need not be present in an update, for example, local preference.
- Optional transitive: Might or might not be recognized by a BGP router but is passed on to other BGP routers. If not recognized, it is marked as partial, for example, aggregator, community.
- Optional nontransitive: Might or might not be recognized by a BGP router and is not passed on to other routers, for example, Multi-Exit Discriminator (MED), originator ID.
Table 6-2. BGP Attributes
|
Attribute |
Meaning |
|
AS path |
An ordered list of all the autonomous systems through which this update has passed. Well-known, mandatory. |
|
Origin |
How BGP learned of this network. i = by network command, e = from EGP, ? = redistributed from other source. Well-known, mandatory. |
|
Local Preference |
A value telling IBGP peers which path to select for traffic leaving the AS. Default value is 100. Well-known, discretionary. |
|
Multi-Exit Discriminator (MED) |
Suggests to a neighboring autonomous system which of
multiple paths to select for traffic bound into your autonomous system.
Lowest MED is preferred. Optional, non-transitive. |
|
Weight |
Cisco proprietary, to tell a router which of multiple
local paths to select for traffic leaving the AS. Highest weight is
preferred. Only has local significance. |
BGP Path Selection Criteria
BGP tries to narrow its path selection down to one best path; it does not load balance by default. To do so, it examines the path attributes of any loop-free, synchronized (if synchronization is enabled) routes with a reachable next-hop in the following order:- Choose the route with the highest weight.
- If weight is not set, choose the route with the highest local preference.
- Choose routes that this router originated.
- Choose the path with the shortest Autonomous System path.
- Choose the path with the lowest origin code (i is lowest, e is next, ? is last).
- Choose the route with the lowest MED, if the same Autonomous System advertises the possible routes.
- Choose an EBGP route over an IBGP route.
- Choose the route through the nearest IGP neighbor as determined by the lowest IGP metric.
- Choose the oldest route
- Choose a path through the neighbor with the lowest router ID.
- Choose a path through the neighbor with the lowest IP address.
Influencing BGP Path Selection
BGP was not created to be a fast protocol; it was created to enable as much administrative control over route path selection as possible. Path selection is controlled by manipulating BGP attributes, usually using route maps. You can set a default local preference by using the command bgp default local-preference and a default MED for redistributed routes with the default-metric command under the BGP routing process. But by using route maps, you can change attributes for certain neighbors only or for certain routes only. The earlier section on route maps contains an example of using a route map to set a local preference of 200 for specific redistributed routes. This is higher than the default local preference of 120, so routers within the AS are more likely to prefer that path than others.Route maps can also be applied to routes sent to or received from a neighbor. The following example shows a simple route map that sets a MED value and adds two more copies of its AS number to the AS path on all routes advertised out to an EBGP neighbor:
route-map MED permit 10 set metric 50 set as-path prepend 65001 65001 ! router bgp 65001 neighbor 10.1.1.1 route-map MED outWhen attributes are changed, you must tell BGP to apply the changes. Either clear the BGP session (clear ip bgp *) or do a soft reset (clear ip bgp * soft in | out). Routers using recent IOS versions do a route refresh when the session in cleared inbound.
Filtering BGP Routes
You can combine route maps with prefix lists to filter the routes advertised to or received from a BGP peer, to control routes redistributed into BGP, and to set BGP attributes for specific routes. Prefix lists alone can be applied to a neighbor to filter route updates.To use a prefix list, plan the implementation by determining the requirements. Then create a prefix list to match the networks to be filtered. Permit the networks you want to allow to be advertised and deny all others. Next apply the prefix list to the BGP neighbor, inbound or outbound. The next example shows a prefix list that permits only summary routes in the 172.31.0.0 network. All other routes are denied by default. The prefix list is then applied to BGP neighbor 10.1.1.1 outbound, so only these routes will be advertised to that peer:
ip prefix-list Summary permit 172.31.0.0/16 le 20 ! router bgp 65001 neighbor 10.1.1.1 prefix-list Summary outTo verify the results of your configuration use the command show ip prefix-list. To clear the counters shown in that command, use the clear ip prefix-list command.
Combine a prefix list with a route map to set attributes on the routes allowed in the prefix list. In the following example, prefix list Summary is used again. A route map sets the Med for those routes to 100 when they are advertised. It sets a Med of 200 for all other routes advertised. The route map is then applied to BGP neighbor 10.1.1.1 outbound:
route-map CCNP permit 10 match ip address prefix-list Summary set metric 100 route-map CCNP permit 20 set metric 200 ! router bgp 65001 neighbor 10.1.1.1 route-map CCNP out
BGP Authentication
BGP supports MD5 authentication between neighbors, using a shared password. It is configured under BGP router configuration mode with the command neighbor {ip-address | peer-group-name} password password. When authentication is configured, BGP authenticates every TCP segment from its peer and checks the source of each routing update. Most ISPs require authentication for their EBGP peers.Peering succeeds only if both routers are configured for authentication and have the same password. If a router has a password configured for a neighbor, but the neighbor router does not, a message such as the following displays on the console while the routers attempt to establish a BGP session between them:
%TCP-6-BADAUTH: No MD5 digest from [peer's IP address]:11003 to [local router's IP address]:179Similarly, if the two routers have different passwords configured, a message such as the following will display on the screen:
%TCP-6-BADAUTH: Invalid MD5 digest from [peer's IP address]:11004 to [local router's IP address]:179
Verifying BGP
One of the best commands to verify and troubleshoot your BGP configuration is show ip bgp to see the BGP topology database. This is such an important command that it's worth looking at in depth. The command output lists a table of all the networks BGP knows about, the next hop for each network, some of the attributes for each route, and the AS path for each route. The sample output from this command was taken from an actual Internet BGP peer.route-server>show ip bgp
BGP table version is 22285573, local router ID is 12.0.1.28
Status codes: s suppressed, d damped, h history, * valid, > best, i
- internal,
r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
* 3.0.0.0 12.123.137.124 0 7018 2914 9304
80 i
*> 12.123.1.236 0 7018 2914 9304
80 i
* 3.51.92.0/23 12.123.137.124 0 7018 ?
* 12.122.125.4 2366 0 7018 ?
*> 12.123.1.236 0 7018 ?
* 8.6.6.0/24 12.123.137.124 0 7018 701 14744
14744 14276 i
* 12.123.145.124 0 7018 701 14744
14744 14276 i
*> 12.123.1.236 0 7018 701 14744
14744 14276 i
Networks are listed in numerical order, smallest to largest. The
first three columns list each route's status. An asterisk (*) in the
first column means that the route has a valid next hop. Some other
options for the first column include the following:- "s" for suppressed: BGP knows about this network but is not advertising it, usually because it is part of a summarized route.
- "d" for dampened: BGP can stop advertising a network that flaps (goes up and down) too often until it is stable for a period of time.
- "h" for history: BGP knows about this network but does not currently have a valid route to it.
- "r" for RIB failure: The route was advertised to BGP but it was not installed in the IP routing table. This might be because of another protocol having the same route with a better administrative distance.
- "S" for stale: Used with nonstop forwarding to indicate that the route is stale and needs to be refreshed when the peer is reestablished.
The third column is blank in the example, which means that the router learned all the routes from an external neighbor. A route learned from an IBGP neighbor would have an "I" in the third column.
The fourth column lists the networks. Those without a subnet mask, such as network 3.0.0.0, use their classful mask. As seen in the example, when the router learns about the same network from multiple sources, it lists only the network once.
The fifth column lists the next-hop address for each route. As you learned in the previous sections on BGP next hops, this might or might not be a directly connected router. A next-hop of 0.0.0.0 means that the local router originated the route.
If a Med value was received with the route, it is listed in the Metric column. Notice that the advertisement for network 3.51.92.0/23 from the router at 12.122.125.4 has a large Med value of 2366. Because the default Local Preference is used for each of the routes shown, no local preference value is displayed. The default Weight value of 0 is listed, however.
The ninth column shows the AS path for each network. Reading this field from left to right, the first AS number shown is the adjacent AS this router learned the route from. After that, the AS paths that this route traversed are shown in order. The last AS number listed is the originating AS. In the example, our router received an advertisement about network 3.0.0.0 from its neighbor AS 7018, which heard about it from AS 2914, which heard about it from AS 9304. And AS 9304 learned the route from AS 80, which originated it. A blank AS path means that the route was originated in the local AS.
The last column shows how BGP originally learned about the route. Networks 3.0.0.0 and 8.6.6.0 show an "i" for their origin codes. This means that the originating router had a network statement for that route. Network 3.51.92.0 shows a "?" as its origin. This means that the route was redistributed into BGP; BGP considers it an "incomplete" route. You will likely never see the third possibility, an "e," because that means BGP learned the route from the Exterior Gateway Protocol (EGP), which is no longer in use.
Some other useful commands for verifying and troubleshooting BGP include
- show ip bgp rib-failure: Displays routes that were not inserted into the IP routing table and the reason they were not used.
- show ip bgp summary: Displays the memory used by the various BGP databases, BGP activity statistics and a list of BGP neighbors.
- show ip bgp neighbors: Displays details about each neighbor. Can be modified by adding the neighbor IP address.
- show ip bgp neighbors address [received | routes | advertised]: Lets you monitor the routes received from and advertised to a particular neighbor.